「America’s AI Action Plan」は、AIにおける米国世界優位の確立、維持を目的に2025年7月発表の戦略計画です。トランプ大統領ビジョンに基づき、AIを経済的繁栄と国家安全保障の鍵と位置づけ、そのための具体行動を3つの柱に分けて提示しています。
これは、America’s AI Action Plan(英文24ページ)をGoogle NotebookLMへアップロードし、得られた日本語概要です。このAmerica’s AI Action Planを題材に、NotebookLMやGemini、CopilotのTipsを示します(Gemini、NotebookLM、Copilot特徴は、前回投稿参照)。
ユーザ資料・分析・整理が得意:NotebookLMのTips
ユーザ資料に情報源を絞り、ハルシネーション抑制も可能な資料解析・分析は、NotebookLMの得意技です。America’s AI Action PlanをNotebookLMへアップすると、冒頭緑で示した概要がそれぞれの母国語で生成されます。3つの柱の説明がこの後に続きます。
America’s AI Action Planは、アメリカという国が、AI世界で一番になるための計画だよ。AIって、みんなが使うスマホのアプリとか、未来の車とか、もっとすごいものを作るのに役立つとっても大事な技術。この計画は、AI分野でアメリカが一番になり、他の国に負けないようにするための「地図」みたいなものだよ。
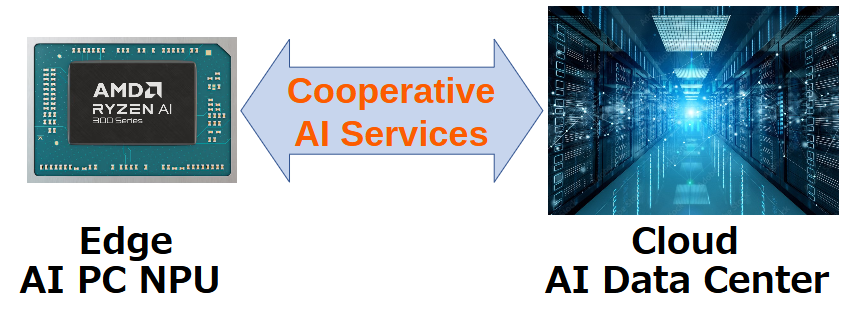
NotebookLMやCopilot出力は、緑字を使いました。本稿とクラウドAI出力を見た目でも分け、Tipsによる出力変化を示すためです。しかし、本来示したかったのは、America’s AI Action Plan概要と現行Copilot+ PCスペックへの影響です。クラウドAIは、同じプロンプトでも状況により出力が変わりますので本稿出力は一例です。各読者でプロンプトを入力し試してください。
3月21日投稿の最新ミニPC記載Ryzen AI 9 HX 370のCPU/GPUを強化したRyzen AI Max+ 395搭載のミニPC発売予告をGMKtec社よりメール受信しました。今ならメールアドレス登録とアンケート回答で、$30割引クーポンゲットのチャンスがあります。
Ryzen AI CPU性能
AMD社のAI PC向けCPU製品名がAPU(Accelerated Processing Unit)です。NPUとGPUをSoCで一体化したCPUのことです。弊社はこのAPUを解り易く「AI CPU」と表記します。現在Ryzen AI CPUは、AI 300とAI Maxの2シリーズが発売中です。
3月21日投稿のAI CPUは、AI 300シリーズのRyzen AI 9 HX 370。発売予告は、より高性能なAI MaxシリーズのRyzen AI Max+ 395です。Ryzen AI CPU性能は、シリーズ名が異なっても最後の数字370や395が性能を表すので判り易いです。
Ryzen AI Max+ 395の内蔵NPUは下表のようにRyzen AI 9 HX 370と同じ50TOPSですが、CPUと内蔵GPUを強化しています。このAI CPU搭載ミニPCが、最初の図のGMKtec社EVO-X2です。NPU+GPU+CPUのトータルAI性能は、126TOPS、70B LLMサポートのミニPCとしては世界初です。
Ryzen AI CPU
Cores /
Threads
Boost2 / Base
Frequency
Cache
Graphics Model
TDP
NPU
TOPS
Ryzen AI Max+ 395
16C/32T
Up to 5.1 / 3.0 GHz
80MB
Radeon 8060S
45-120W
50
Ryzen AI 9 HX 370
12C/24T
Up to 5.1 / 2.0 GHz
24MB
Radeon 890M
15-54W
50
Ryzen AI Max+ 395搭載EVO-X2
Ryzen AI MaxとAI 300の2シリーズでNPU性能が同じ理由は、AMD/Intel/Qualcomm 3社のAIアプリ共通実行環境が無いこと、ビジネスAIキラーアプリが無いことだと思います(NPU懸念投稿に詳細記載)。さらに、50TOPSのNPUでエッジAI PCに十分かは、前回投稿AI PC NPU役割で示したように不明です。
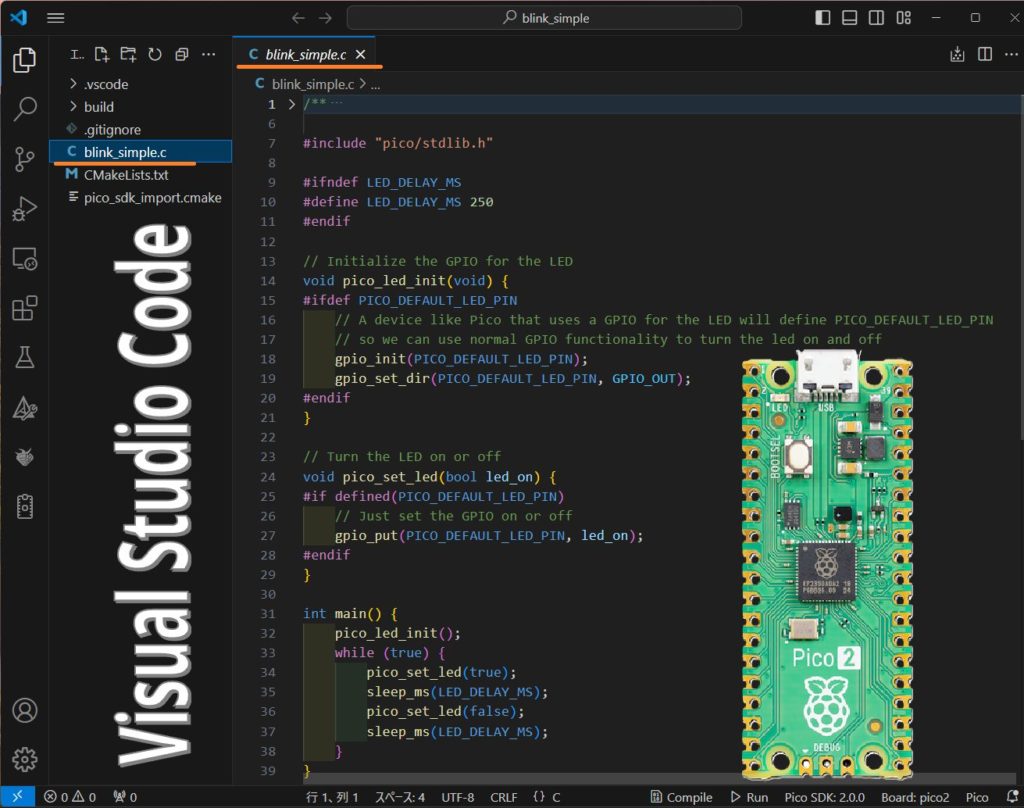
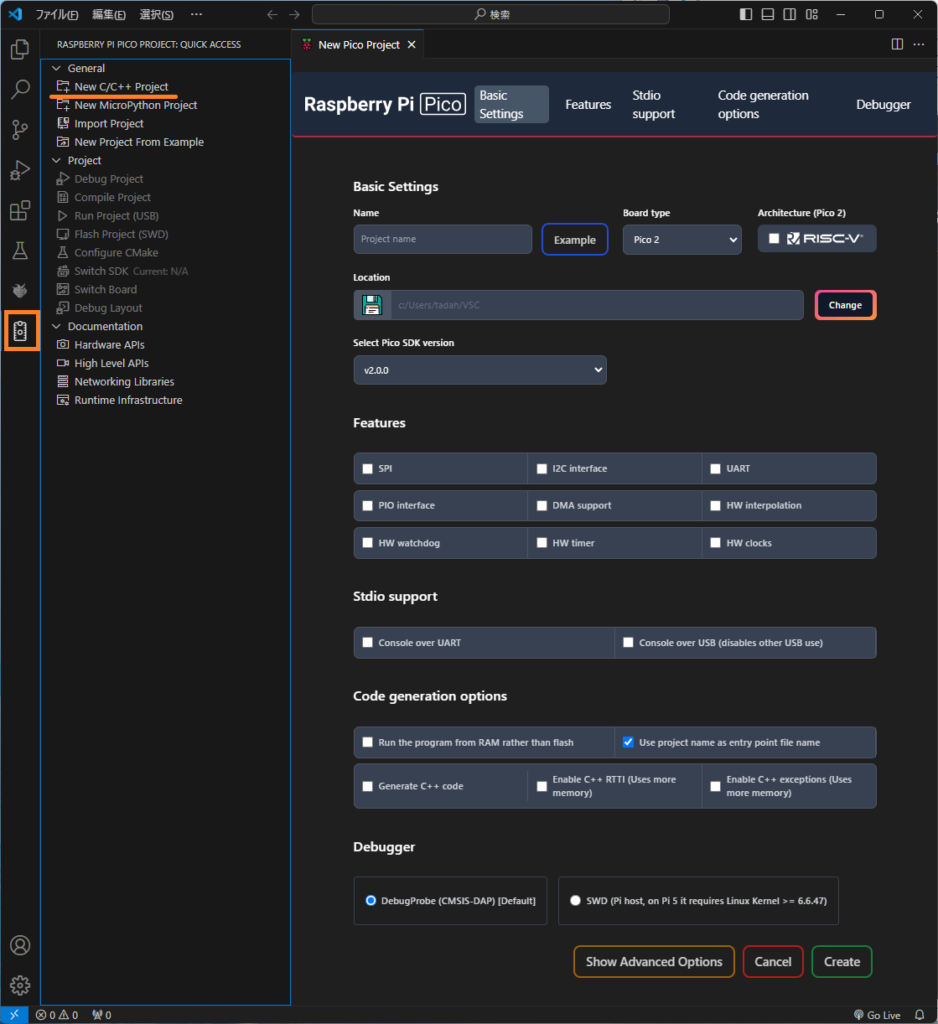
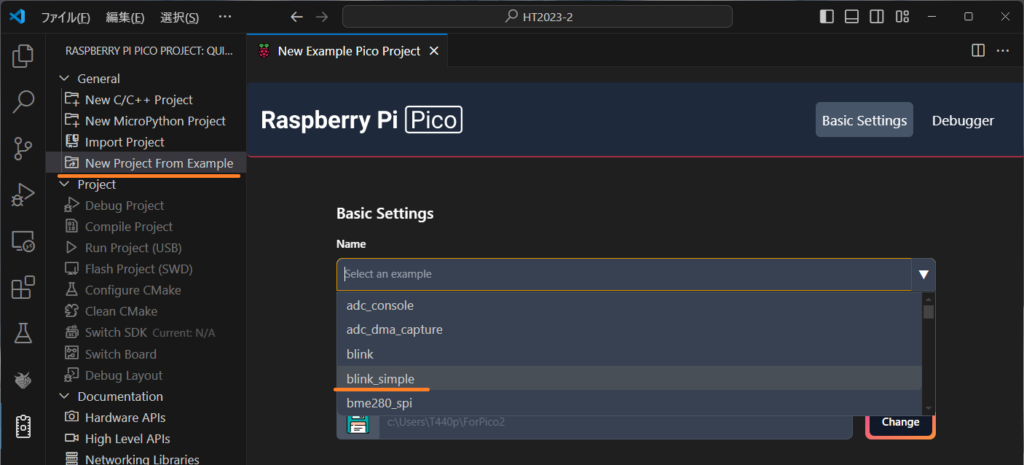
New C/C++ Projectの3つ下New Project From Exampleをクリックし、Name欄にblink_simple、Board typeはPico 2を選択します。Locationに適当な保存先を入力し、これ以外はデフォルトでCreateをクリックするとサンプルコード:blink_simple.cが作成されます。
※Name右横▼から様々なサンプルコード選択可能。
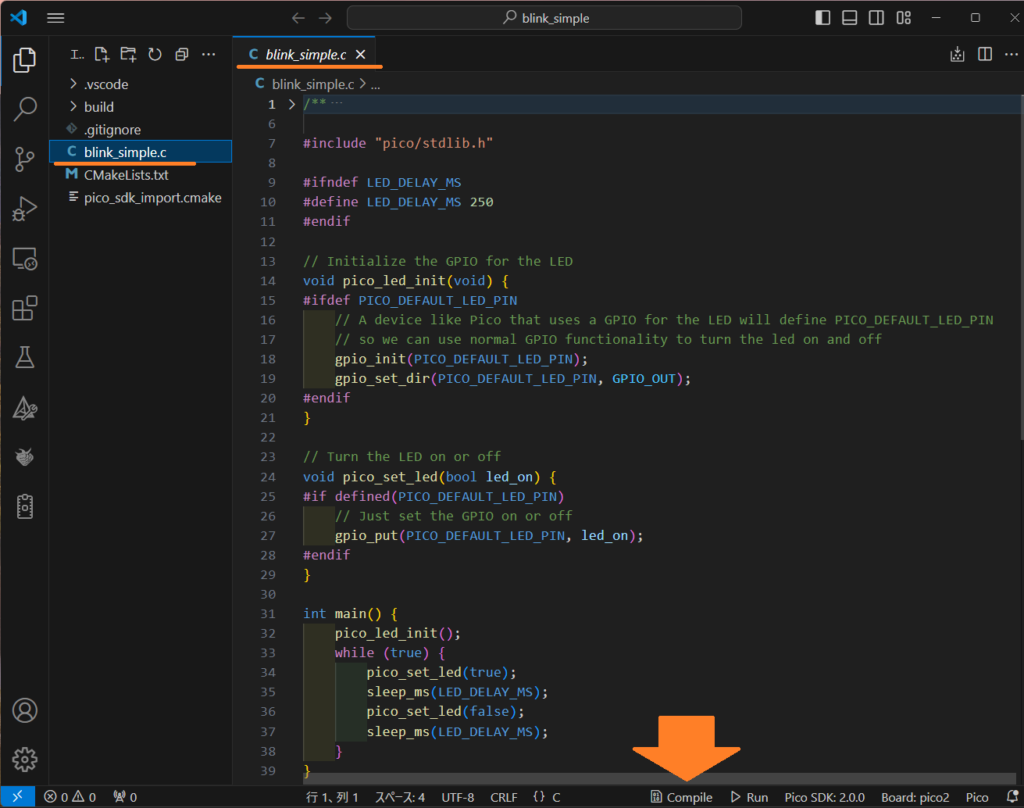
最初はDownloading SDK and Toolchainなどがあるため、作成時間がかなりかかります。画面右下のステータスで状況が判ります。また、「作成者を信頼しますか」などの質問が来ることもあります。暫く待っていると、下記blink_simple.cが現れます。