ルネサスの業績が黒字に回復し、「縮小と撤退」から「拡大と攻勢」へ転換したそうです。うれしいです。このルネサスからRL78/I1Dという新しいRL78マイコンが2月に発売されました。方針転換後に厳選した新製品と思われるので、その情報から最新マイコントレンドを考えました。
従来RL78マイコンと新マイコンRL78/I1Dの違い
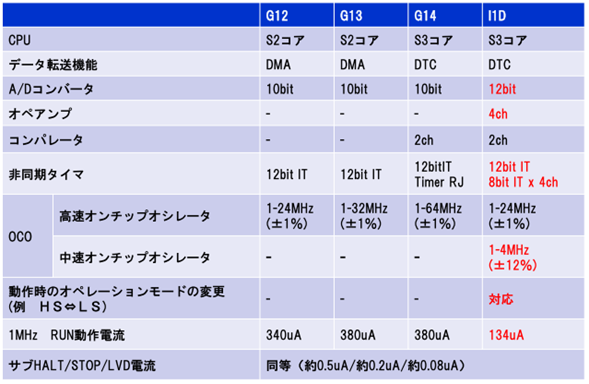
「RL78/I1D」ご紹介資料P11から、従来RL78/G13、G14とRL78/I1Dの差が解ります。RL78/I1Dは、S3コアで、ADC分解能、オペアンプ、RUN動作電流などの機能が強化されています。また、従来RL78では、動作電圧に応じてオペレーションモードが固定であったのが、ソフトで変更できるようになりました。これにより、電源電圧が低下しても機能停止せず、しかもRUN動作電流も激減しましたので、長い期間マイコンが動作可能です。
さらに、非同期タイマも追加され、センサの長時間間欠動作もCPU停止:STOPのまま可能となりました。CPU起動は、「高速wakeup」対応の中速オンチップオシレータを使うと4us程度で可能です。
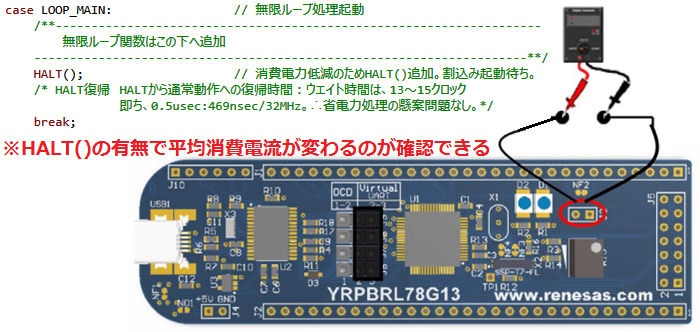
※RL78/G1xテンプレートは、CPU:HALTで低消費電力対応しているため、0.5us/32MHzで起動します。
ADCの計測データは、DTCで直接RAMへ転送可能です。DTCとは、簡単に言うと、DMAがメモリアクセス専用のCPU代替転送機能なのに対し、より複雑なCPU代替処理にも対応できるものです。
マイコンドレンド:省エネとIoT
2010年発売の汎用マイコンRL78/G13やG14との違いから明らかなように、最新マイコンRL78/I1Dは、オペアンプ内蔵や高速オンチップオシレータ上限が24MHz、48ピンまでの小パッケージサイズなどから、センサアプリに特化したマイコンです。
RL78/G14の高速オンチップオシレータの実質周波数上限は32MHzなので、I1DのS3コア性能は多少劣りますが、低消費電力とより低電圧での動作など、そのトレンドは、「省エネ」追求です。
IoTでは、このRL78/I1Dのような省エネマイコンが数百億個使われと予想され、価格は、使用個数に応じて激減しますので、RL78/I1DもG13やG14と同程度、またはより低価格になるかもしれません。このように、IoTアプリケーション向けの周辺回路を持つ省エネマイコンでのシェア獲得がルネサスの狙いでしょう。汎用マイコンの機能を、IoTに会わせて見直した結果とも考えられます。
RL78/I1D CPUボード入手できず

RL78/G1xテンプレートは、このRL78/I1Dへそのまま流用できるハズです。DTCやADCなどの周辺回路制御は、機種毎に異なりますが、テンプレート本体は、マイコンやベンダが異なっても基本的に同一だからです。
※RL78の場合は、ショート・ダイレクト・アドレッシングsreg領域を使ってARMマイコンテンプレートと比べて、少しチューニングしています。
RL78/I1DのCPUボード:RTE5117GC0TGB00000Rでテンプレートを試そうとしましたが、2015年2月現在、個人向け販売サイトには残念ながら見つかりません。入手可能になれば試す予定です。RL78/I1DがIoT汎用マイコンになる可能性が高いからです。
マイコントレンドに合わせたIoTテンプレート
従来テンプレートは、シンプルテンプレート(テンプレート動作理解が目的)と、メニュードリブンテンプレート(所望処理の簡単な取出しが目的)の2本立てでした。
マイコンドレンドが「省エネ」で、DTCやDMAを使った「マイコン内データ転送も、汎用化」しつつあるので、これらに合わせたアプリテンプレート:IoTテンプレート(仮称)も今後検討したいと思います。